Abstract
Long-form video understanding represents a significant challenge within computer vision, demanding a model capable of reasoning over long multi-modal sequences. Motivated by the human cognitive process for long-form video understanding, we emphasize interactive reasoning and planning over the ability to process lengthy visual inputs. We introduce a novel agent-based system, VideoAgent, that employs a large language model as a central agent to iteratively identify and compile crucial information to answer a question, with vision-language foundation models serving as tools to translate and retrieve visual information. Evaluated on the challenging EgoSchema and NExT-QA benchmarks, VideoAgent achieves 54.1% and 71.3% zero-shot accuracy with only 8.4 and 8.2 frames used on average. These results demonstrate superior effectiveness and efficiency of our method over the current state-of-the-art methods, highlighting the potential of agent-based approaches in advancing long-form video understanding.
💡 Introduction
VideoAgent employs a large language model as an agent to mirror the human cognitive process for understanding long-form videos, which effectively searches and aggregates information through a multi-round iterative process.
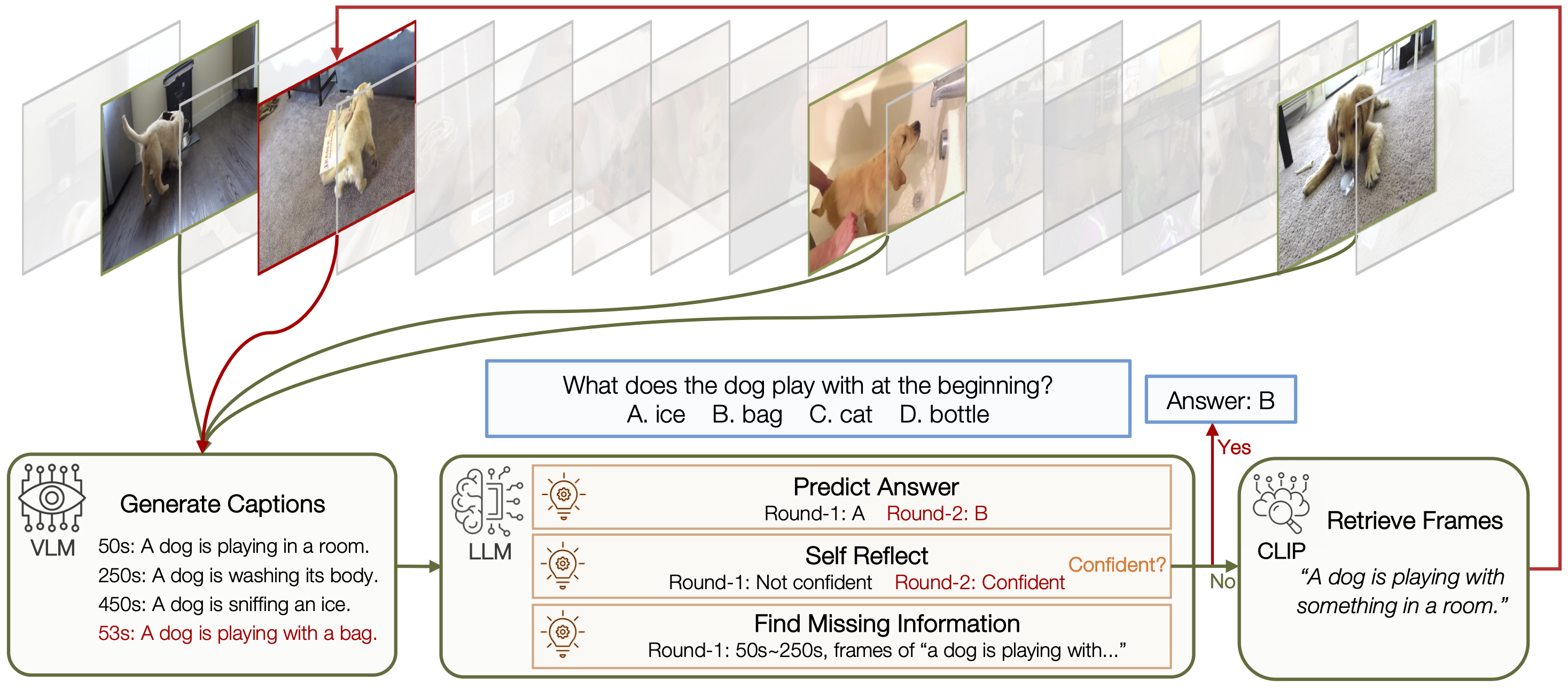
Given a long-form video, VideoAgent iteratively searches and aggregates key information to answer the question. The process is controlled by a large language model (LLM) as the agent, with the visual language model (VLM) and contrastive language-image model (CLIP) serving as tools.
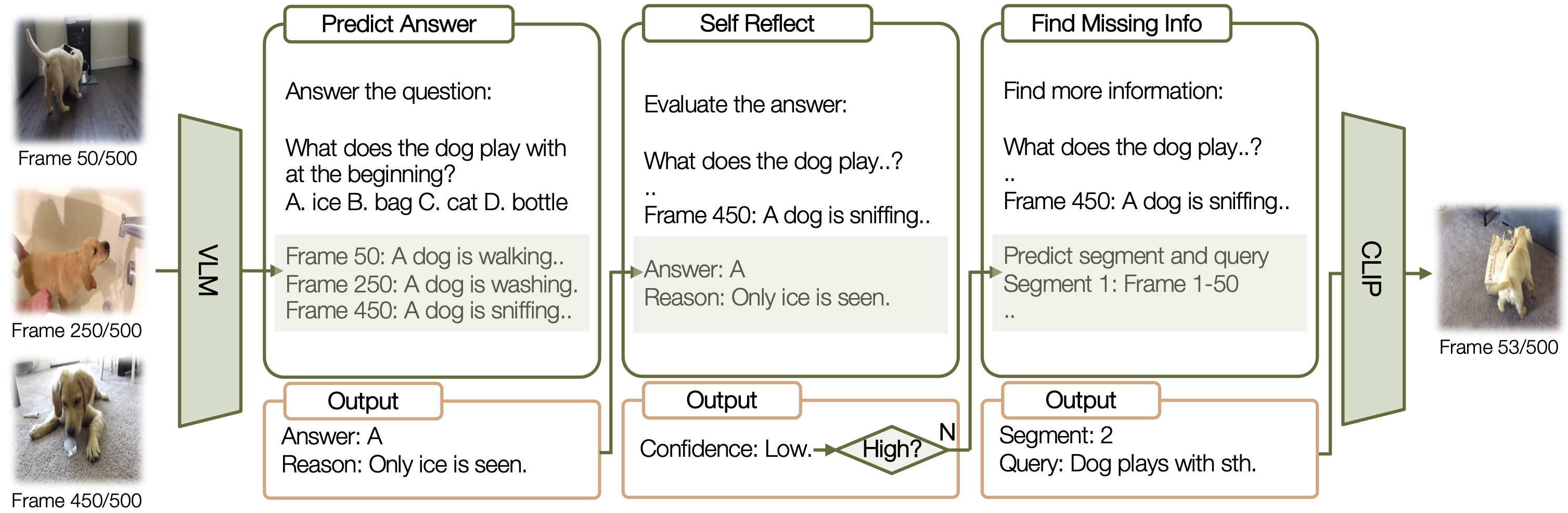
Each round starts with the state, which includes previously viewed video frames. The large language model then determines subsequent actions by answering prediction and self-reflection. If additional information is needed, new observations are acquired in the form of video frames.
📈 Results
VideoAgent sets new benchmarks, achieving state-of-the-art (SOTA) results on the EgoSchema and NExT-QA datasets, surpassing previous methods significantly while requiring only a minimal number of frames for analysis.
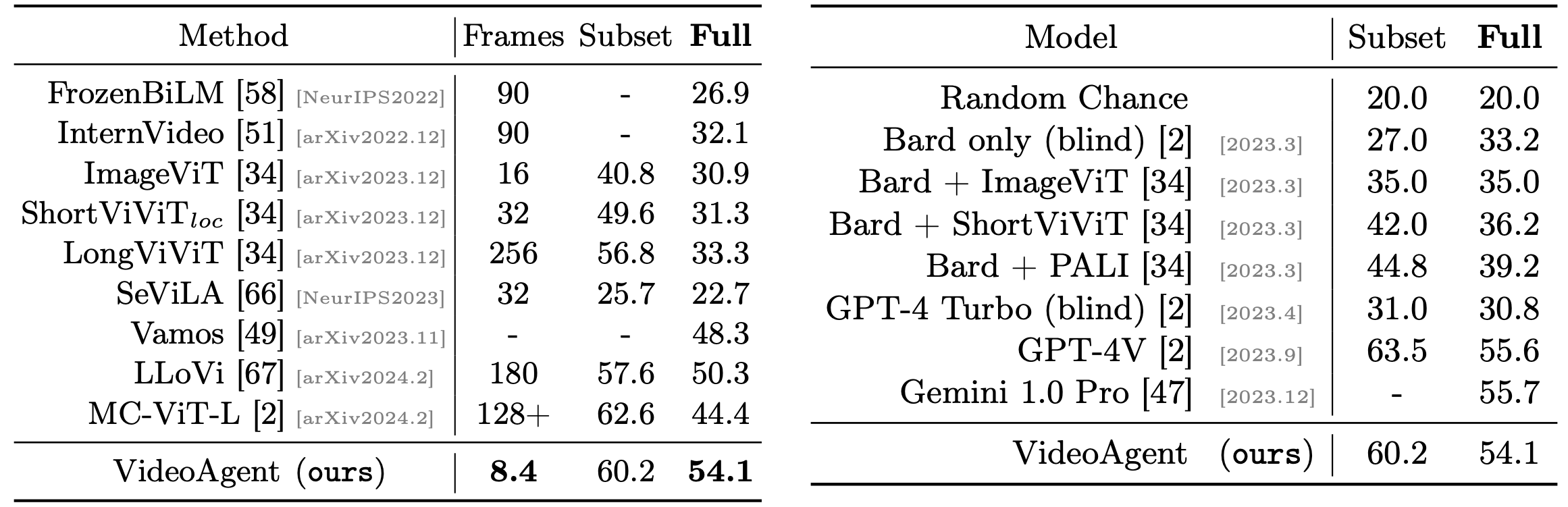
Results on EgoSchema compared to public models (left) and large-scale proprietary models (right). Full-set results are obtained from the official leaderboard.
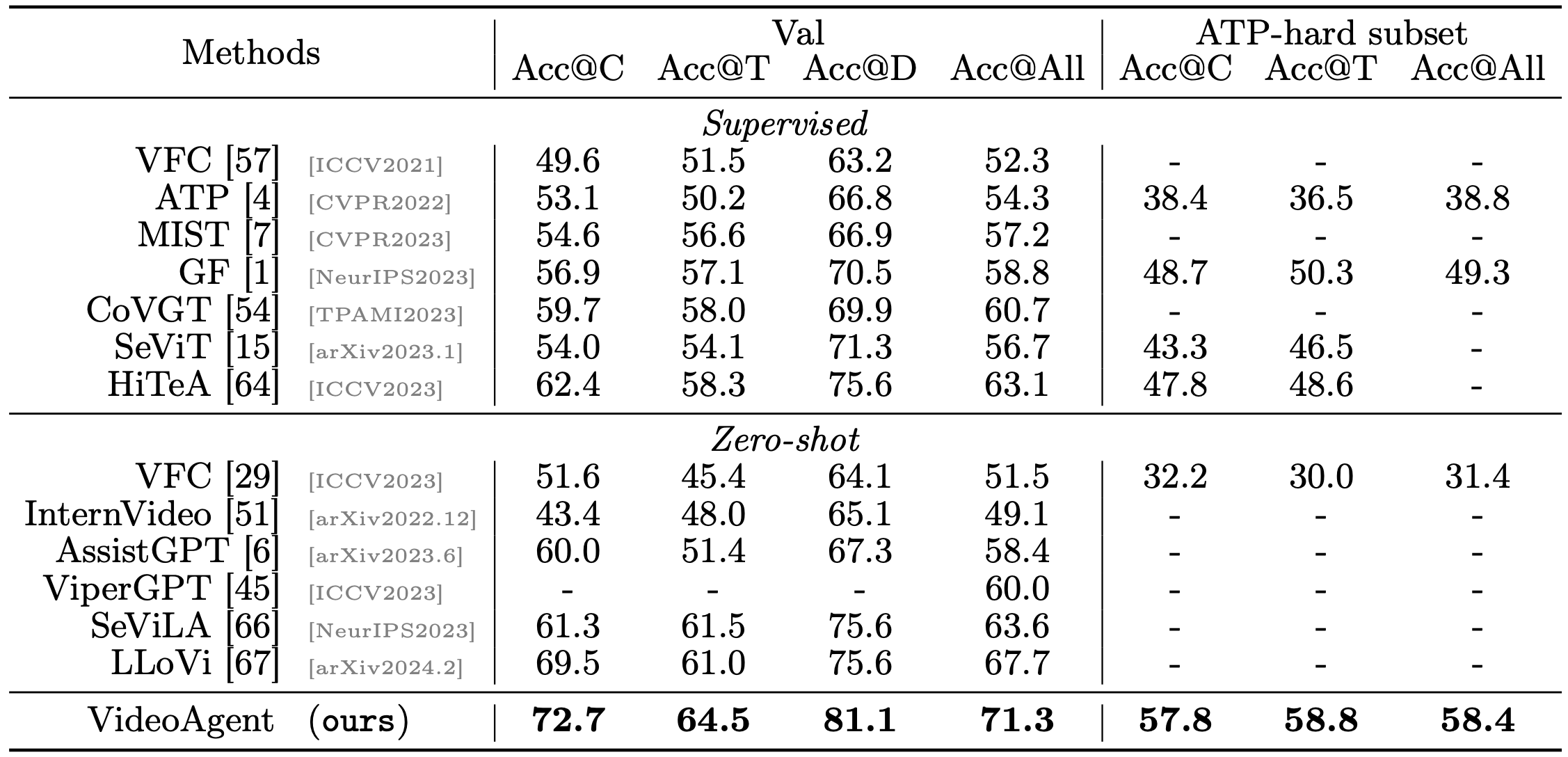
Results on NExT-QA compared to the state of the art. C, T, and D are causal, temporal, and descriptive subsets, respectively.
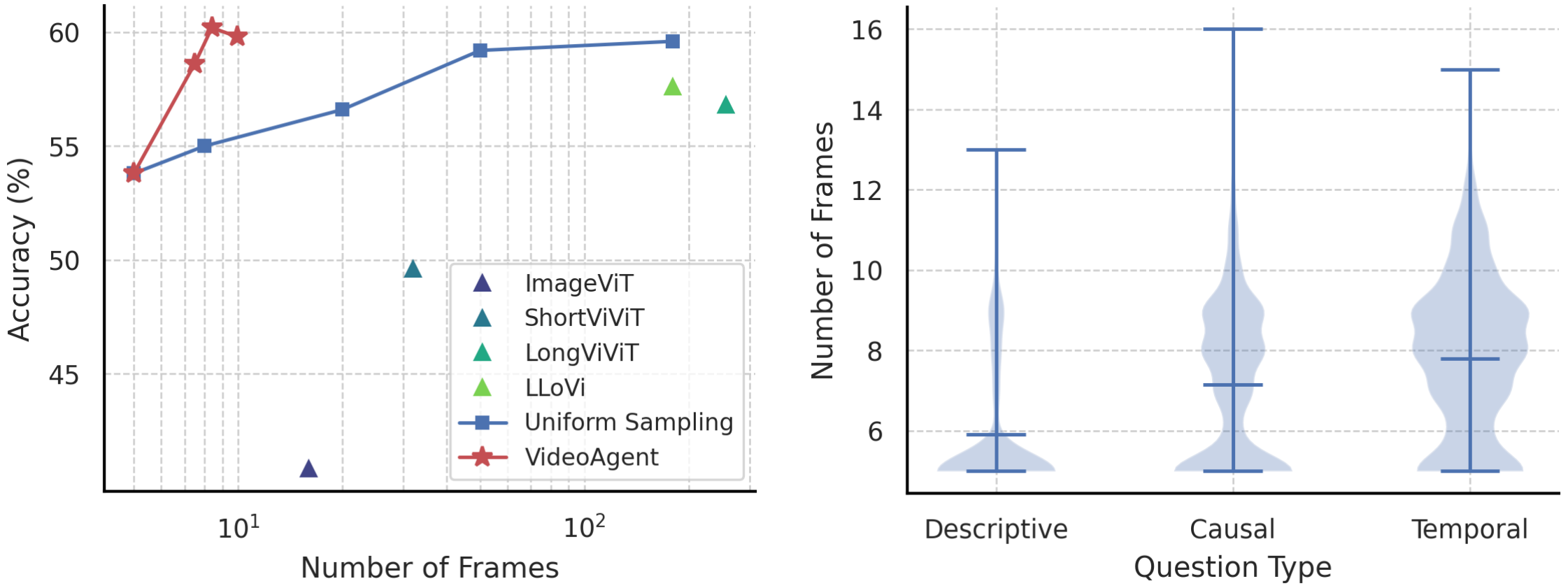
(Left) Frame efficiency compared to uniform sampling and previous methods. X-axis is in log scale. Our method achieves exceptional frame efficiency for long-form video understanding. (Right) Number of frames for different types of NExT-QA questions. Min, mean, max, distribution are plotted. VideoAgent selects more frames on questions related to temporal reasoning than causal reasoning and descriptive questions.
🔮 Case Study
We present two case studies to demonstrate the capability of VideoAgent in understanding long-form videos.

Given a video from NExT-QA, VideoAgent accurately identifies missing information in the first round, bridges the information gap in the second round, and thereby makes the correct prediction.

Given an hour-long video, VideoAgent accurately identifies the key frame during the second iteration, subsequently making an accurate prediction. Conversely, GPT-4V, when relying on 48 uniformly sampled frames up to its maximum context length, does not get successful prediction. However, by integrating the frame pinpointed by VideoAgent, GPT-4V is able to correctly answer the question.
BibTeX
@article{VideoAgent,
title={VideoAgent: Long-form Video Understanding with Large Language Model as Agent},
author={Wang, Xiaohan and Zhang, Yuhui and Zohar, Orr and Yeung-Levy, Serena},
journal={European Conference on Computer Vision (ECCV)},
year={2024}
}